Redis基础与概念
[TOC]
Redis概念与基础
1. Redis基本概念、特点
Redis是一款内存高速缓存数据库,作为非关系型数据库,其不是采用表的形式存储数据。
Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统)。
-
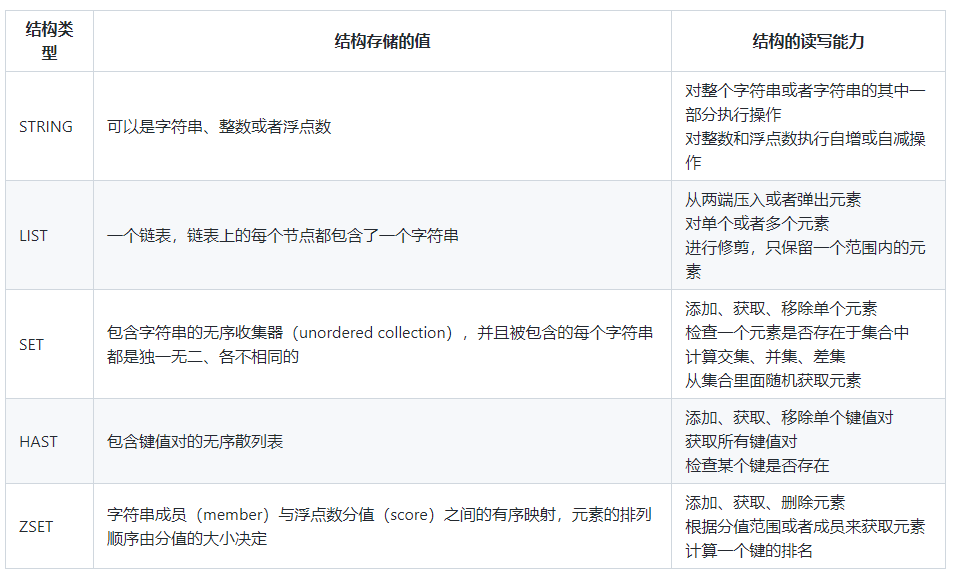
Redis不是一个普通的key-value存储系统,它实际上是一个数据结构服务器,支持不同类型的值。如:String、list、set、zset、hash等。
-
单线程操作(Redis其实不是单线程,fysnc file descriptor进行持久化)
-
Redis的key是二进制安全的,这意味着您可以使用任何二进制序列作为键,从“ foo”这样的字符串到 JPEG 文件的内容。空字符串也是一个有效的键。但是太长或太短的key都不建议使用,需要兼顾效率与可读性,一般采用“object-type:id"的形式。
-
优点:读写性能优异、数据类型丰富、原子性操作(合并)、持久化操作(快照或日志)、分布式特点。
2. Redis数据类型与简单命令操作
-
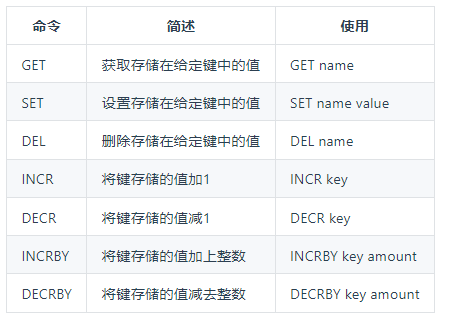
STRING
1set key value [EX seconds] [PX ms] [nx|xx]-
常用命令
-
命令执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world" 127.0.0.1:6379> del hello (integer) 1 127.0.0.1:6379> get hello (nil) 127.0.0.1:6379> get counter "2" 127.0.0.1:6379> incr counter (integer) 3 127.0.0.1:6379> get counter "3" 127.0.0.1:6379> incrby counter 100 (integer) 103 127.0.0.1:6379> get counter "103" 127.0.0.1:6379> decr counter (integer) 102 127.0.0.1:6379> get counter "102" -
实战场景
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源
- session:常见方案spring session + redis实现session共享
-
-
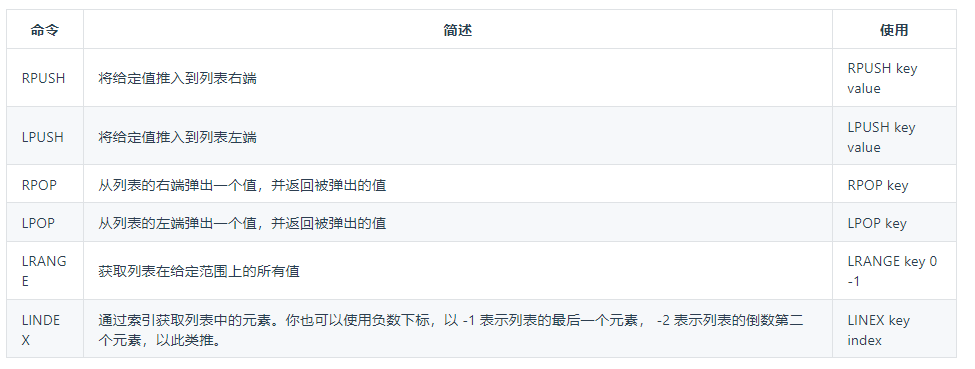
LIST
Redis中的List其实就是链表(Redis用双端链表实现List)。
-
常用命令
-
命令执行
1 2 3 4 5 6 7 8 9 10 11 12 13127.0.0.1:6379> lpush mylist 1 2 ll ls mem (integer) 5 127.0.0.1:6379> lrange mylist 0 -1 1) "mem" 2) "ls" 3) "ll" 4) "2" 5) "1" 127.0.0.1:6379> lindex mylist -1 "1" 127.0.0.1:6379> lindex mylist 10 # index不在 mylist 的区间范围内 (nil) -
实战场景
- 微博TimeLine: 有人发布微博,用lpush加入时间轴,展示新的列表信息。
- 消息队列
-
-
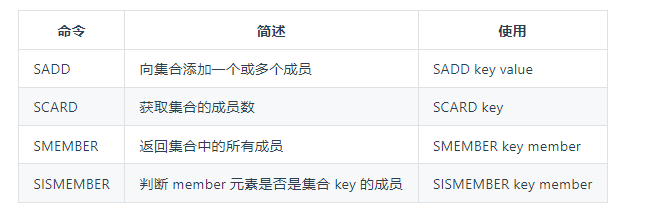
SET
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
-
常用命令
-
命令执行
1 2 3 4 5 6 7 8 9127.0.0.1:6379> sadd myset hao hao1 xiaohao hao (integer) 3 127.0.0.1:6379> smember myset 1) "xiaohao" 2) "hao1" 3) "hao" 127.0.0.1:6379> sismember myset hao (integer) 1 -
实战场景
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现
-
-
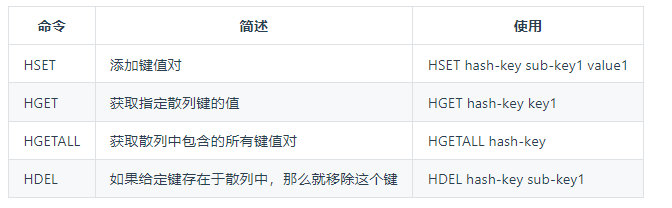
HASH
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
-
常用命令、
-
命令执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26127.0.0.1:6379> hset user name1 hao (integer) 1 127.0.0.1:6379> hset user email1 hao@163.com (integer) 1 127.0.0.1:6379> hgetall user 1) "name1" 2) "hao" 3) "email1" 4) "hao@163.com" 127.0.0.1:6379> hget user user (nil) 127.0.0.1:6379> hget user name1 "hao" 127.0.0.1:6379> hset user name2 xiaohao (integer) 1 127.0.0.1:6379> hset user email2 xiaohao@163.com (integer) 1 127.0.0.1:6379> hgetall user 1) "name1" 2) "hao" 3) "email1" 4) "hao@163.com" 5) "name2" 6) "xiaohao" 7) "email2" 8) "xiaohao@163.com" -
实战场景
- 缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
-
-
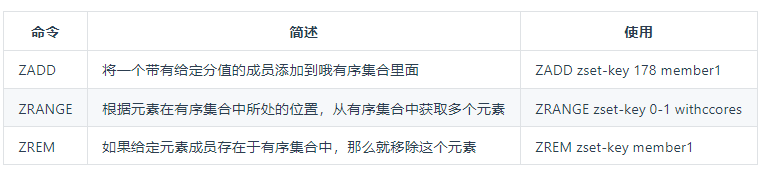
ZSET 有序集合
-
常用命令
-
命令执行
1 2 3 4 5 6 7 8127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao (integer) 2 127.0.0.1:6379> ZRANGE myscoreset 0 -1 1) "xiaohao" 2) "hao" 127.0.0.1:6379> ZSCORE myscoreset hao "100" -
实战场景
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行
-
3. 使用场景
-
计数器
可以对 String 进行自增自减运算,从而实现计数器功能。
Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。
-
缓存
将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
-
查找表
例如 DNS 记录就很适合使用 Redis 进行存储。
查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源。
-
消息队列
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息
不过最好使用 Kafka、RabbitMQ 等消息中间件。
-
会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。
当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
-
分布式锁
-
点赞、好友等相互关系存储
Redis 利用集合的一些命令,比如求交集、并集、差集等。
在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
-
排行榜
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
比如点赞排行榜,做一个SortedSet, 然后以用户的openid作为上面的username, 以用户的点赞数作为上面的score, 然后针对每个用户做一个hash, 通过zrangebyscore就可以按照点赞数获取排行榜,然后再根据username获取用户的hash信息,这个当时在实际运用中性能体验也蛮不错的